Details
-
Type:
 Bug
Bug
-
Status: Closed
-
Priority:
 Major
Major
-
Resolution: Fixed
-
Affects Version/s: 4.1.1
-
Fix Version/s: 4.2
-
Component/s: Core/Parsing
-
Labels:None
-
Environment:-
-
Assignee Priority:P1
Description

Activity
- All
- Comments
- History
- Activity
- Remote Attachments
- Subversion
The issue seems to root itself from the cmap parsers in both the os and pro versions. If we take the "after" word as an example it is actually only made up of 4 character codes not five. The "ft" glyph is represented by code 02 but the toUnicode mapping is actually [<00660074>] or "f" and "t".
For example in the toUnicode cmap.
4 beginbfrange
<02> <02> [<00660074>]
<03> <03> [<006600660069>]
<04> <04> [<00540068>]
<05> <05> [<00660069>]
In this case parse the file without error but we don't correctly retrieve the whole uncode value. so for 02 we return 0066 and not 00660074. Should be pretty quick fix in both products and will improve the OS font substitution.
It turns out that there was a bug in our content parser logic and cmap logic. When text extraction takes place the toUnicode cmaps are used to map a CID to a String. In our old code we would make a CID to a char but there cases where CID can be represented by more then character.
In the Pro version the issue only showed up with text extraction as it uses the toUnocide cmaps. A little work had to be done to fix the cmap parsing issue. The problem didn't show up at render time because Pro can property read and render CID fonts.
In the OS version the issue showed up at render time and during text extraction. Some work had to be done to first correct the cmap parsing error so we could get the correct String for a given CID and the OFont class was updated to layout and draw the extra characters found in the returned Cmap string.
[ Show » ]
Patrick Corless added a comment - 24/Feb/11 12:52 PM It turns out that there was a bug in our content parser logic and cmap logic. When text extraction takes place the toUnicode cmaps are used to map a CID to a String. In our old code we would make a CID to a char but there cases where CID can be represented by more then character. In the Pro version the issue only showed up with text extraction as it uses the toUnocide cmaps. A little work had to be done to fix the cmap parsing issue. The problem didn't show up at render time because Pro can property read and render CID fonts. In the OS version the issue showed up at render time and during text extraction. Some work had to be done to first correct the cmap parsing error so we could get the correct String for a given CID and the OFont class was updated to layout and draw the extra characters found in the returned Cmap string.
the code for this bug was checked in accedentally under PDF-228, -r24000
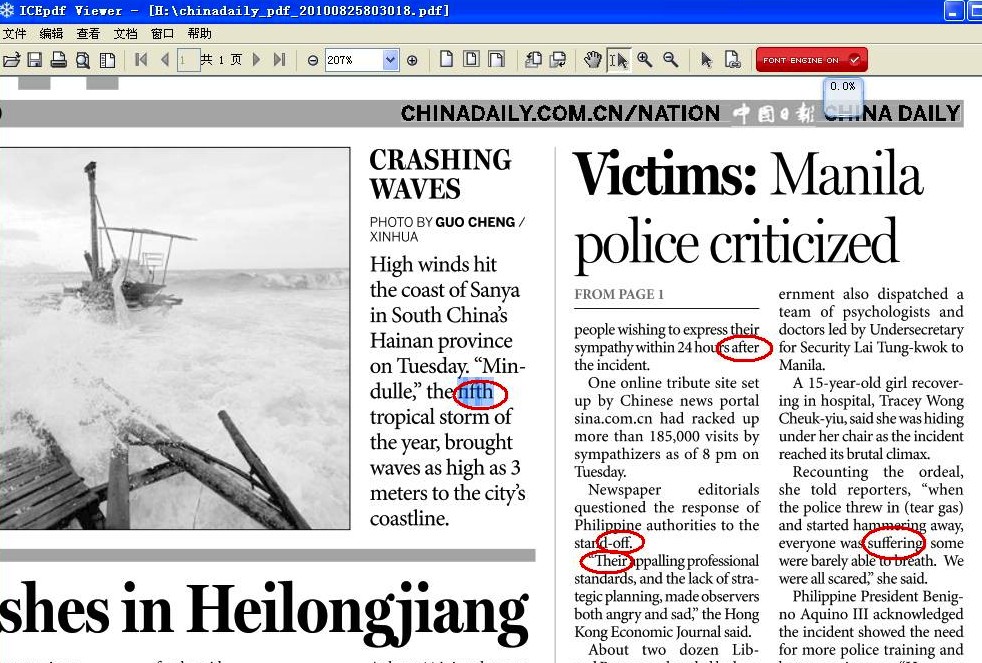
The issue still exists in 4.2. For example, attempting to copy the next in the attached screenshot results in the word fifth being copied as f f h like so:
High winds hit
the coast of Sanya
in South China's
Hainan province
on Tuesday. "Min-
dulle," the f f h
tropical storm of
the year, brought
waves as high as 3
meters to the city's
coastline.
Attaching a second test case which is shows the issue in better detail. At the top of the PDF, "These fine ffine ften ffton flen fflen" copies as "Tese fne fne fen fon fen fen".
The original issue is fixed from my testing both on the OS and PRO version for the original file 9589_test.pdf on Windows. The file should work on Mac as well given the nature of the issue but I could be wrong.
I've create PDF-280 to capture the issue define in the new test file.
I'll have to take a closer look next week. Generally speaking there should be a entry in the toUnicode to handle the conversion but I guess that is difficult given the one to two mapping. Interestingly enough acrobat doesn't do a stellar job either. I suspect the we'll have ot put in some stiffer code to look for these types of glyphs.